Parkour_Bot CS 175: Project in AI (in Minecraft)
Final Report
Video
Project Summary
The goal of this project was to create a “parkour” Agent that could both traverse a three-dimensional path that may contain obstacles such as raised platforms or stairs to reach a desired destination. The agent would utilize deep reinforcement learning to optimize its actions, in order to reach the end goal in fewer steps and shorter times. More specifically, the agent would start on a stone block and learn to go through a diamond path while avoiding obstacles in order to reach checkpoints represented by gold blocks and the end goal represented by an emerald block.
The desired outcome would be for the agent to use continuous movement commands in order to traverse the path with the same range of movement as a human player, as opposed to the limited range of discrete movement commands. Using reinforcement learning, the agent should be able to develop a sense for the path that would allow it to traverse the path safely and as quickly as possible while gaining the highest reward overall. This project is also separate from projects relating to pathfinding algorithms as it is intended to learn a specified path/course as opposed to finding its own calculated path.
Approaches
The first approach used in this project was purely using Malmo and a Q-Network similar to the one used in Assignment 2. Here, the given internal network was replaced with a more robust system using a series of linear layers with a LeakyReLU activation function, creating a deep q network by increasing the number of hidden layers. This method was used until after the first status report, after which it was clear that, while it did train quickly with this method and reach the end goal on straight simple paths, it would be unable to make a sharp turn on a test map due to the limited action space as well as its simple implementation.
It was here that the implementation of this agent was replaced with the one recommended by the TA. Using RLlib and the included PPO algorithm, a continuous action space was created with values ranging from -1 to +1, with three different action types: move, turn, and jump. Move and turn were both left in their continuous states, though for the sake of faster training and knowing that the agent should always move forward and not backward for our purposes, any negative move values were replaced with positive ones equivalent in magnitude. Jumping was made binary, with any positive value starting the jump action and any zero or negative value stopping the jump action. This allowed the agent to turn faster and move slower than before when necessary, allowing it to make the turn instead of overshooting and falling into the lava surrounding the path.
The agent was tested and trained on several different short paths testing different aspects of the agent’s intended abilities. For example, there was a simple straight path for basic testing, followed by a straight path with a raised block to jump over as well as the sharp turn and a path with stairs. To shorten the overall testing time, group members were assigned to paths and asked to train the algorithm for an extended period of time and upload the return graph to the git repository.

Evaluation
Reward function
For each run, the agent is rewarded 10 points for moving to a new block on the diamond path, 50 points for reaching the gold checkpoint, 100 points for reaching the emerald end goal, and falling into lava or staying at the starting stone block result in -1 point each. We also add a -1 point for every tick of a second, which sums up to -20 points every second, to encourage our agent finding the end goal in the shortest time.
Algorithm
Until after the first status report, we were still using a Deep Q-Network implementation with a robust system using series of hidden linear layers and a LeakyReLU activation function. The result showed that our agent was able to quickly recognize the correct direction to move but unable to decide the better path in that direction, as the return graph fluctuates quite a lot in value and does not improve over time. After trying out a new implementation using PPO algorithm included in RLlib, the return graph showed a steady increase in return value over time, but the growth was very slow suggested that longer training time is necessary for success.
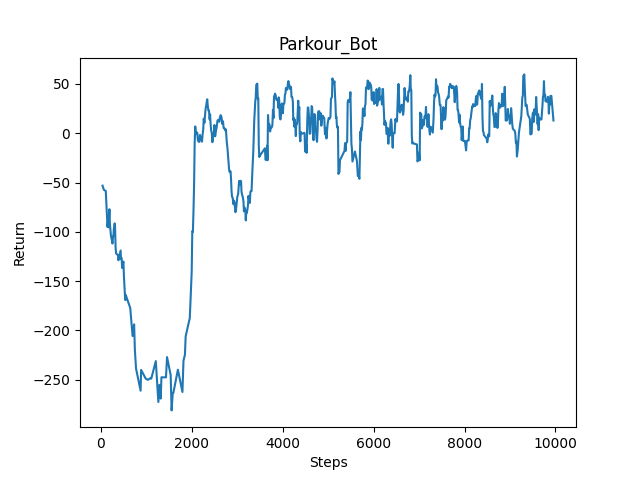
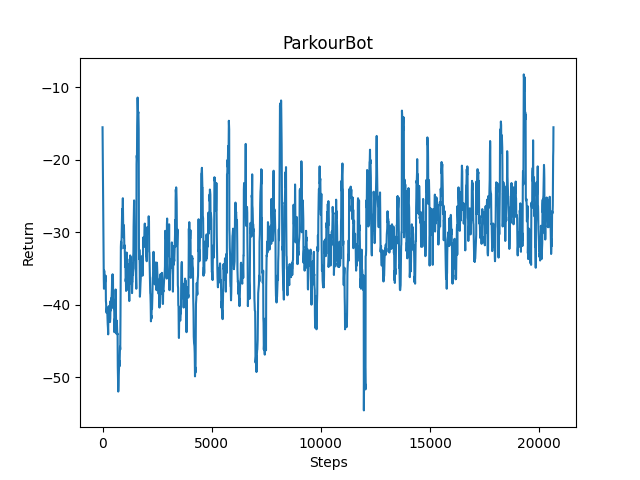
Training result
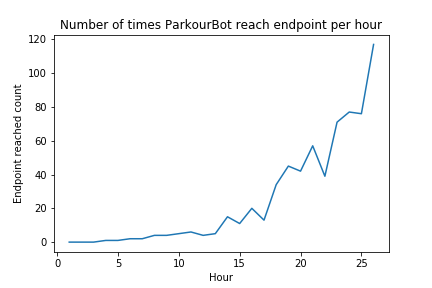
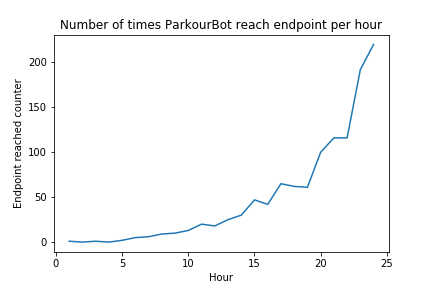
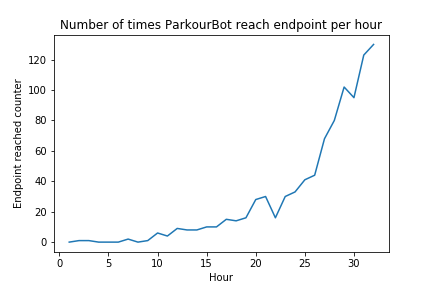
The agent was trained on several different short paths testing different aspects of the agent’s intended abilities. Particularly, we focused on three paths demonstrating three separate abilities: one block jump path, sharp turn path, and consecutive block jump path. After a period of 24 hours of time, with some opting for slightly longer periods, the return graphs showed a positive trend which seemed to show that the agent was learning slowly but surely through this extended training.

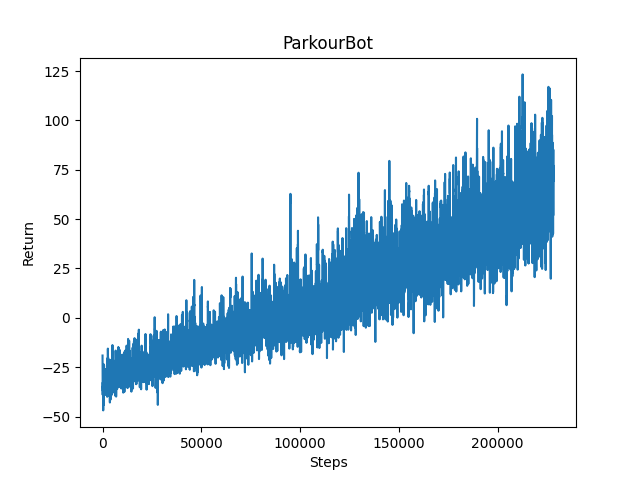
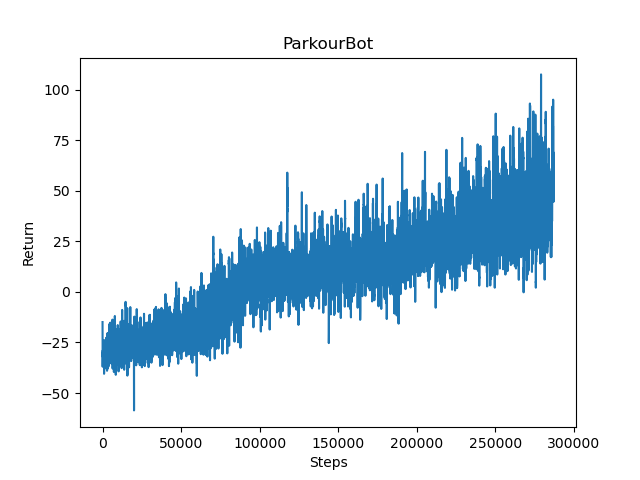
When observing the agent’s behavior during training, this finding was supported. After 24 hours, the agent would be able to find the end goal fairly consistently, much more often than it could at the beginning of the training. During the last hour of training, the agent recorded 150 times reaching the end goal on average of 750 runs per hour, while being able to show the intended ability (one block jump, sharp turn, consecutive block jump) and reaching checkpoint before the end goal.
Conclusion
Due to the wide range of return values that could be found due to the wide variety of changes that could be made to the rewards, it is clear that the primary criteria for evaluating the agent is external behavior after extended training and not the return values on their own. The returns did show a positive trend as time went on, but the agent was still making many mistakes here and there even after training. It is assumed that these errors are within reasonable limits given than the agent is in the middle of training while logging these returns and therefore is expected to explore and fail often in order to learn as much as possible about its immense domain of states and actions. The ability of the agent to find the end goal fairly often while still training suggests that the agent has learned the given path and training it for even longer periods of time would risk overfitting it to a certain path.
For the purposes of this project, the problem at hand has been solved as the returns and external behavior of the agent both suggest its ability to learn a path with the aid of checkpoints and end goal rewards. This project, of course, can still benefit from future improvement. For example, with more time, it would be possible to rigorously test different parameters as well as different networks among a wide range of randomly generated paths, which, after training across a large number of paths for extended periods, may allow the algorithm to become more generalized. This would evolve this agent from one that is able to learn any path to one that does not have to learn a new path and can instead intuit the correct actions to take to get to an end goal efficiently. However this would require a vast amount of testing time and experimentation with new neural networks and algorithms which would take it outside the scope of this class. In any case, this project has shown success as well as promise.
References
PPOtrainer https://spinningup.openai.com/en/latest/algorithms/ppo.html
Malmo Reinforcement Learning(RLIB) https://www.youtube.com/watch?v=v_cDSTfk5A0&feature=youtu.be
Gym API https://www.youtube.com/watch?v=rTVYgBzMNPo&feature=youtu.be
RLlib https://docs.ray.io/en/latest/rllib.html
Pytorch Documentation https://pytorch.org/docs/stable/index.html